
ELK uses a watermark, when disk space reaches X% (90% I believe), it stops performing, and shuts down services. For this reason it’s important to have a good sense of data maintenance.
How long do you need your data? 5 days? 7 days? 30 days?
How much disk space do you have available to you? 100G? 300G? 1Tb? Unlimited?
Answering those questions, and knowing the rate of growth for your most active indexes sets the tone for how often indexes will be rolled over and deleted.
Elastic Search has an interesting way of managing file / data size on a host. It’s managed through the Index Lifecycle Management (ILM for short). This is found in the main menu, via Stack Management / Index Management.
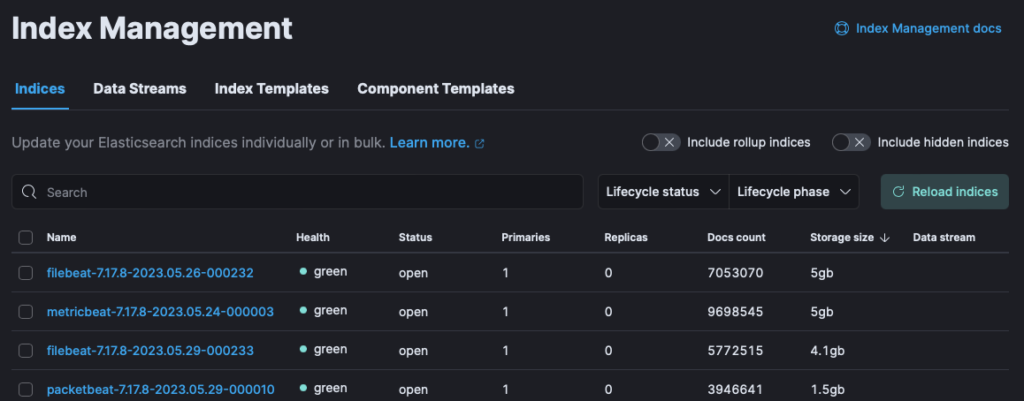
In the screenshot above, I’m sorting by the largest sized indexes. I have some 5G filebeat, metricbeat and a 1.5G packetbeat indexes. In this scenario I’ve set a 5G cap, so the indexes roll over at 5G and after 2 days the old indexes are deleted.
If you’ve had problems setting this up in ELK, then read through this post as it might just answer the problems.
Problem: Index Outgrows the Defined Limits
When I first tried to cull my indexes and make sure they didn’t grow beyond a certain size, I noticed they always ignored my rules. I also noticed my indexes were all Yellow (Health was Yellow).
Fixing Yellow Indexes
While ELK worked fine, all my indexes early on were of Yellow Health. I couldn’t find much details about it, but I noticed that on my Index details, it showed a Replica of 1. Reading some official documentation I discovered that ELK will not create a replica in the primary node.
In other words, if you have a simple setup of:
Cluster 1: Node: 1: Running ELK
If you install ELK on one machine/vm then you’re likely running in one Cluster and have 1 Node. As such, according to the documentation linked above, there is no replica.
What is a Replica?
From the documentation, “A replica shard is a copy of a primary shard. Replicas provide redundant copies of your data to protect against hardware failure and increase capacity to serve read requests like searching or retrieving a document.”
Adding Replicas
I’ve seen various write-ups showing diagrams where a replica shard exists on the primary node. In practicality it seems this isn’t possible, as the official documentation from elastic says:
If you are running a single instance of Elasticsearch, you have a cluster of one node. All primary shards reside on the single node. No replica shards can be allocated, therefore the cluster state remains yellow.
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/add-elasticsearch-nodes.html
Adding other ELK nodes in a cluster will open up the possibility for replicas. On a separate machine/vm create a new ELK node, but update the elasticsearch.yml so that the cluster has the same ID as your primary. Add a node name in the yml file so that it is unique (Node2), and have your primary node named as well (Node1).
Removing Replicas
However, if your project doesn’t require replicated data (i.e. you keep data for a short period and delete it), you can remove your replicas.
- Click on an Yellow Index in the Index Management screen
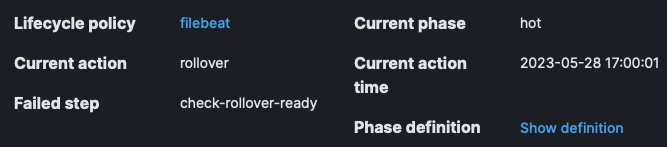
- A side detail pane opens up. Click on the linked Lifecycle Policy (see below screenshot: the “filebeat” link is an example)
- In the Lifecycle policy Details, go to the Warm Phase. If it is off, turn it on.
- In the Warm Phase open “Advanced Details” and turn on Replicas, then set the value of Replicas to 0
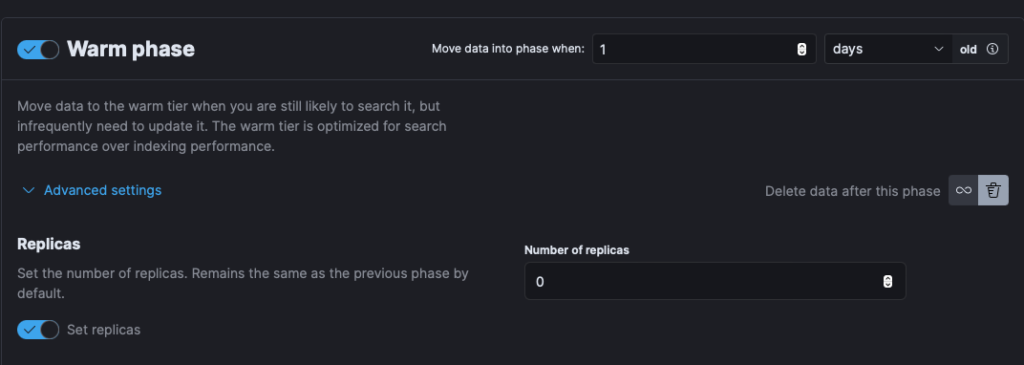
- If your intent is to delete an index in this phase, set the amount of days you want to keep warm (how long to keep the old index), and then check the “Delete Data after this phase” option (see screenshot above).
Repeat the steps above for each Yellow Index.
NOTE: if your goal is to rotate out logs after X Gigs or X Days, while in the Index Lifecycle Detail screen, you can set those values in the HOT Phase Advanced Details.
Commands / Queries to Run
To run Queries/commands in ELK, you can get to the dev console by clicking in the search field in Kibana and typing Dev.
Dev Tools will appear in the drop down. Click it.
On the left side, you enter your queries, and on the right is the result. After entering a query on the left, click the play icon to the right of your line:

Queries to check the health of your cluster:
GET _cluster/health/
# To get more details on the cluster:
GET _cluster/allocation/explainTo set the replicas to 0, for the primary index:
PUT _settings
{
"index.number_of_replicas": 0
}